La résolution distribuée de problèmes et, plus généralement, l’IA distribuée est un courant de pensée déjà ancien. L’idée de résolution distribuée de problèmes remonte au milieu des années 1970 avec d’une part, les langages d’acteurs et d’autre part, le modèle d’architecture de tableau noir ou blackboard, initialement proposé pour la compréhension automatique de la parole et largement repris par la suite. Dans un système d’IA distribuée, un ensemble d’entités autonomes, appelées agents, interagissent pour mener à bien une tâche contribuant à la résolution d’un problème complexe. Le concept d’agent a été l’objet d’étude, non seulement en IA, mais aussi en philosophie ou en psychologie. Avec le développement de l’Internet, on a assisté à l’apparition de nombreuses dénominations, françaises ou anglaises : agent ressource, agent courtier, assistant personnel, agent mobile, agent web, agent interface, chatbot, softbot, knowbot, avatar, etc.
De façon générale, un agent est une entité informatique, située dans un environnement, et qui agit d’une façon autonome pour atteindre les objectifs pour lesquels elle a été conçue. Ces agents peuvent être aussi des entités physiques (machines, robots manipulateurs, etc.) : le domaine est alors celui des systèmes multirobots.
On peut définir deux grandes catégories d’agents :
- les agents réactifs dotés de simples réflexes stimulus-action. Dans ce modèle, d’inspiration notamment biologique (abeilles, fourmis, termites, araignées sociales…), des comportements intelligents peuvent émerger des interactions par échanges de signaux entre les agents d’un système ;
- les agents cognitifs, plus complexes et dotés de capacités de raisonnement sur une base de connaissances (représentation du monde, des autres agents, etc.) et de mécanismes élaborés d’interaction entre agents. Nous nous limitons ici à ce type d’agents.
La figure montre la structure d’un agent cognitif. Un tel agent doit posséder les propriétés suivantes :
- l’autonomie, la capacité à prendre des initiatives et à agir sans intervention de l’utilisateur final ;
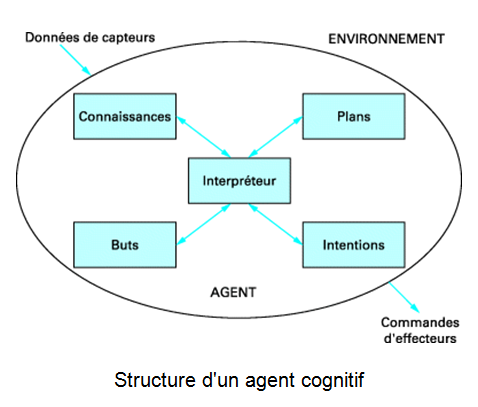{kind=link}
- la perception de l’environnement ;
- l’aptitude à communiquer, à échanger et à coopérer avec d’autres agents, des serveurs de données ou des utilisateurs humains ;
- le raisonnement fondé sur les connaissances disponibles ;
- l’adaptation à l’environnement et à son évolution.
La communication entre agents, garant de l’efficacité de leur collaboration, ressortit à deux grands mécanismes : le partage d’informations et l’envoi de messages caractéristique des systèmes à objets et des systèmes multiagents.
Ces deux mécanismes de base résultent en des architectures très différentes. Dans les systèmes à partage d’informations, il existe une zone de mémoire commune (base de faits généralisée ou tableau noir, blackboard ) qui centralise toutes les communications entre agents. De ce fait, ces communications sont implicites : les agents s’ignorent mutuellement, il n’existe pas de lien direct entre eux. Initialement proposé pour la compréhension automatique de la parole et la vision par ordinateur dans les années 1970, ce modèle a été largement repris par la suite. Il est maintenant abandonné au profit de systèmes dans lesquels les agents communiquent entre eux de façon explicite en s’envoyant des messages de complexité très variable selon les systèmes et relevant de différents types d’interaction, compétition, coopération et négociation, avec modification dynamique des liens entre agents. Citons comme exemple le réseau de contrat (Contract Net ) permettant de mettre en relation plusieurs agents de façon analogue à un appel d’offres. La communication entre agents nécessite un partage de connaissances et une préservation de la sémantique des entités manipulées par les agents. Cela est assuré par l’utilisation d’ontologies.
Les applications des agents sont nombreuses et diverses :
- la robotique : systèmes multirobots ;
- la simulation : les systèmes multiagents sont bien adaptés à la simulation car ils permettent de représenter séparément les rôles et les connaissances d’entités autonomes et de modéliser leurs interactions. Plusieurs plates-formes logicielles permettent de développer de telles applications, par exemple Cougar, Jade, Madkit ;
- la modélisation de phénomènes complexes : dans des domaines tels que les sciences de la vie (colonies d’insectes, écosystèmes, etc.), la défense, l’économie ;
- Internet : de très nombreuses applications relèvent de ce domaine. Il existe une grande variété d’agents sur Internet : moteurs et métamoteurs de recherche d’informations généraux ou spécialisés par domaines, surveilleurs de sites Web, agents commerciaux, agents de loisirs, agents de recommandation (ces agents constituent un type de filtrage collaboratif permettant de proposer à un client potentiel des produits susceptibles de l’intéresser en se fondant sur trois types de connaissances : les propriétés de l’objet recherché, le comportement passé du client et le comportement de clients jugés semblables. Un exemple type est le système Amazon) ;
- l’assistance aux personnes : assistants virtuels, agents domotiques… ;
- les avatars : ces agents d’un nouveau type aident l’utilisateur à naviguer sur un site complexe (musées, grands magasins, opérateurs téléphoniques, etc.).
Le modèle d’agent est désormais central en IA et plus généralement en Informatique. Les agents intelligents et les systèmes multiagents ont un rôle important dans la recherche et dans la gestion des connaissances. L’évolution vers le Web sémantique passe aussi par une meilleure exploitation par des agents des informations disséminées sur la toile. Parmi beaucoup d’initiatives, on peut signaler la méthode Linked Data (ou Web des données) proposée T. Berners-Lee pour poster sur Internet des données pouvant être reliées entre elles et facilement exploitées par des agents ou des êtres humains. L’objectif est de favoriser la publication de données structurées sur le Web, non pas sous la forme de sources isolées, mais en les reliant entre elles pour constituer un réseau global d’informations. Les principes de base du projet sont simples :
- utiliser d’une part le modèle de données RDF pour publier des données structurées sur le Web ;
- utiliser d’autre part des liens RDF pour interconnecter les données provenant de sources différentes.
Exclusif ! L’article complet dans les ressources documentaires en accès libre jusqu’au 4 novembre !
Systèmes à bases de connaissances, un article de Jean-Paul HATON, Marie-Christine HATON
Dans l'actualité
- Turfu Festival : zoom sur un projet robotique open source et une intelligence artificielle
- En image : les propositions de Villani en faveur de l’intelligence artificielle
- Nouveaux matériaux : du biomimétisme à l’intelligence artificielle
- L’intelligence artificielle Google DeepMind prête à détrôner le cerveau humain
- L’intelligence artificielle inamicale : réalité ou fantasme ?
- Facebook choisit Paris pour implanter son centre européen dédié à l’Intelligence artificielle
- L’intelligence artificielle joue aux jeux d’arcade
- Des machines qui se souviennent, le défi des intelligences artificielles à venir
- Google DeepMind : la machine surpasse une nouvelle fois l’intelligence humaine
- L’intelligence est-elle le fruit d’un accident génétique survenu il y a 550 millions d’années ?
- L’Europe et IA : mobilisation générale
- L’IA, au coeur de la réindustrialisation française
- Domotique : Free fait irruption dans la maison connectée
- De la vie artificielle quantique a été créée dans le cloud
- Une intelligence artificielle bon marché ?
- L’intelligence artificielle booste les recherches en toxicité
- Simsoft Industry : un assistant vocal dédié au monde de l’industrie
- Quand l’intelligence artificielle vient au secours de la découverte scientifique
- Cybersécurité : l’intelligence artificielle n’est pas l’arme fatale !
- L’intelligence artificielle, une aide à la conception des robots mouche
- Chatbots et IA : des assistants virtuels dotés de personnalité ?
Dans les ressources documentaires