







Des chercheurs ont développé un outil de modélisation de type apprentissage automatique pour détecter les populations les plus susceptibles d'être touchées par la faim. Il repose sur l'utilisation de données publiques facilement accessibles et a été testé au Burkina Faso.
Pour détecter les populations les plus susceptibles d’être touchées par la faim, une approche classique consiste à réaliser des enquêtes ménages en se déplaçant sur le terrain de manière à appréhender au plus près les familles et leur consommation alimentaire. Cette méthode permet d’obtenir de nombreux indicateurs de sécurité alimentaire pertinents et utiles, parmi lesquels deux sont particulièrement exploités par les organisations étatiques et les ONG : le score de consommation alimentaire (SCA) et le score de diversité alimentaire (SDA). Très précieux pour la compréhension de la situation alimentaire, ces indicateurs présentent tout de même l’inconvénient de nécessiter des enquêtes longues et coûteuses.
Une équipe de scientifiques du Cirad (Centre de coopération internationale en recherche agronomique pour le développement) a développé une nouvelle méthode d’approximation de ces indicateurs, plus facile à mettre en œuvre. Elle vient d’être testée avec des résultats prometteurs au Burkina Faso et a fait l’objet d’une publication dans la revue Expert Systems With Applications. Les chercheurs ont utilisé des indicateurs indirects de la faim, provenant de données publiques et donnant une information partielle mais significative sur le niveau d’insécurité alimentaire, comme la météo, la densité de population, la répartition des hôpitaux et des écoles sur un territoire, les prix du maïs… « Savoir quel est le nombre d’hôpitaux et leur localisation n’est pas une information directe de l’insécurité alimentaire, mais donne une indication sur le niveau sanitaire d’un territoire. Et l’on sait que ces deux composantes, alimentaires et sanitaires, sont corrélées », analyse Hugo Deléglise, docteur en science des données au Cirad.
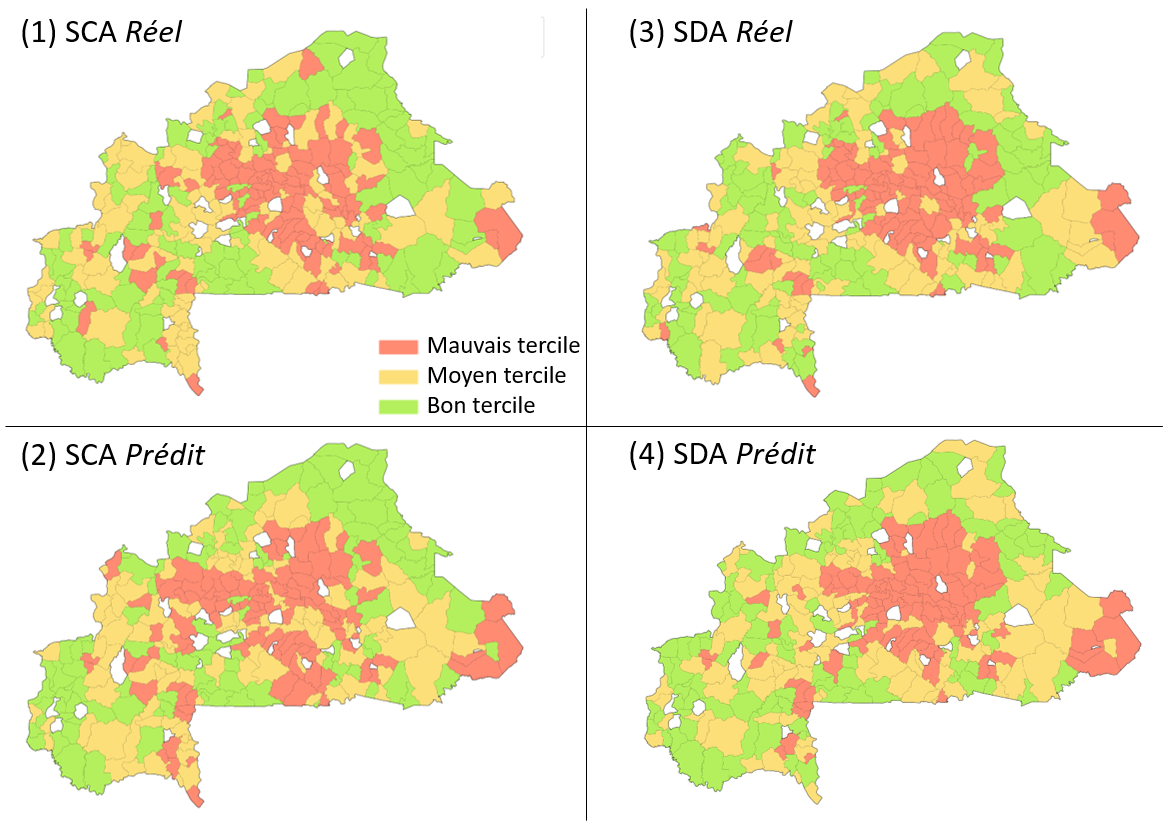
Au total, plus de 120 variables indirectes de la faim ont été retenues, puis intégrées dans un outil de modélisation de type apprentissage automatique (machine learning). Face à la complexité des données, certaines pouvant être des valeurs numériques, des images ou des textes, ce travail de recherche a également nécessité l’emploi de modèles de type réseau de neurones (deep learning). L’algorithme a ensuite été entraîné sur un historique de données de 10 années, et grâce aux enquêtes sur le terrain effectuées au Burkina Faso depuis 2009, des liens de corrélation avec les deux scores d’insécurité alimentaire (SCA et SDA) ont pu être effectués.
L’altitude des communes a une incidence sur l’insécurité alimentaire
Depuis plusieurs dizaines d’années, les experts utilisaient déjà un grand nombre des 120 variables dans leurs analyses pour détecter les zones les plus touchées par la faim. L’originalité de cette nouvelle approche utilisant l’intelligence artificielle est que le modèle est guidé par les données elles-mêmes et non par des règles fixées empiriquement par des humains. « Du coup, certains liens peuvent être contre-intuitifs, ajoute le chercheur. Par exemple, il est apparu que l’altitude moyenne de chaque commune a une incidence relativement importante sur l’insécurité alimentaire. Cette variable n’est pas très utilisée par les experts, ou alors ne figure certainement pas parmi les plus importantes. On peut s’apercevoir à quel point une variable peut peser sur le résultat final, mais sans vraiment pouvoir interpréter les liens de causalité. »
Sur la dernière année de l’enquête ménage disponible au Burkina Faso et menée en 2018, les scientifiques ont pu évaluer les performances de leur modèle sur sa capacité à prédire les deux indicateurs de l’insécurité alimentaire. Résultat, le score de consommation alimentaire est prédit avec un coefficient R2 de 0,57 et celui sur la diversité alimentaire de 0,58. En sachant qu’une valeur proche de zéro correspond à une prédiction très hasardeuse et qu’elle devient parfaite lorsqu’elle tend vers un. « À partir d’un coefficient de 0,6, on peut considérer comme envisageable une utilisation de notre modèle par les acteurs qui interviennent sur le terrain, poursuit Hugo Deléglise. Nous y sommes donc presque. Il va être possible de l’améliorer au fur et à mesure des années, car plus on a d’historique de données, et plus l’algorithme pourra établir des règles de corrélation sûres et sophistiquées. Nous souhaitons également poursuivre notre travail de recherche pour intégrer de nouvelles variables dans notre modèle. »
Et quid de la prise en compte de l’impact du récent coup d’État militaire dans ce pays sur l’insécurité alimentaire ? « L’algorithme intègre déjà les situations de conflits survenant dans un pays grâce à une variable provenant de l’ACLED (Armed Conflict Location & Event Data Project), un organisme qui recense tous les événements violents dans le monde, répond le chercheur. Mais cette source d’information est trop partielle, et nous poursuivons nos travaux pour ajouter des données textuelles issues de journaux. L’idée est d’extraire automatiquement des informations sur les situations alimentaires et les crises publiées sur des sites en ligne. »
Dans tous les cas, ce nouveau modèle peut se révéler très utile dans les pays soumis à des situations de crise, où les enquêtes auprès des populations ne peuvent plus être réalisées, car il devient trop dangereux de se déplacer sur le terrain.










Réagissez à cet article
Vous avez déjà un compte ? Connectez-vous et retrouvez plus tard tous vos commentaires dans votre espace personnel.
Inscrivez-vous !
Vous n'avez pas encore de compte ?
CRÉER UN COMPTE